1. Download or create sample csv
vi test.csv
id,name,amount
1,Ola McGee,40
2,Callie Taylor,65
3,Jesus Kennedy,43
4,Irene Freeman,56
5,Essie Carson,40
6,Marc McCarthy,62
7,Nicholas Snyder,37
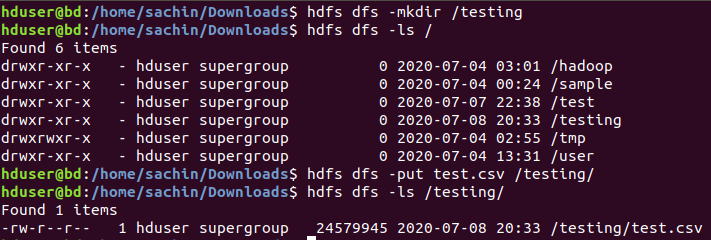
2. Insert test.csv into Hadoop directory testing
#Create testing directory in hadoop
hduser@bd:/home/sachin/Downloads$ hdfs dfs -mkdir /testing hduser@bd:/home/sachin/Downloads$ hdfs dfs -ls / Found 6 items drwxr-xr-x - hduser supergroup 0 2020-07-04 03:01 /hadoop drwxr-xr-x - hduser supergroup 0 2020-07-04 00:24 /sample drwxr-xr-x - hduser supergroup 0 2020-07-07 22:38 /test drwxr-xr-x - hduser supergroup 0 2020-07-08 20:33 /testing drwxrwxr-x - hduser supergroup 0 2020-07-04 02:55 /tmp drwxr-xr-x - hduser supergroup 0 2020-07-04 13:31 /user hduser@bd:/home/sachin/Downloads$ hdfs dfs -put test.csv /testing/ hduser@bd:/home/sachin/Downloads$ hdfs dfs -ls /testing/ Found 1 items -rw-r--r-- 1 hduser supergroup 24579945 2020-07-08 20:33 /testing/test.csv
3. CREATE four Tables in hive for each file format and load test.csv into it
PLAIN TEXTFILE FORMAT
#LOGIN INTO HIVE BEELINE
hduser@bd:~/hiveserver2log$ beeline beeline> !connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000:
Enter password for jdbc:hive2://localhost:10000:
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000>
#CREATE TABLE plain_text
0: jdbc:hive2://localhost:10000>CREATE EXTERNAL TABLE plain_text
(
id integer,
name STRING,
age integer
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/testing/'
TBLPROPERTIES ('skip.header.line.count'='1');INFO : Starting task [Stage-0:DDL] in serial mode
OK
INFO : Completed executing command(queryId=hduser_20200708204042_62691f18-d1ea-4bf9-9e77-a57bea02f91e); Time taken: 1.786 seconds
INFO : OK
INFO : Concurrency mode is disabled
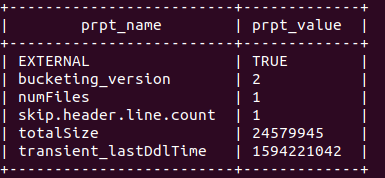
#CHECK THE TABLE SIZE
0: jdbc:hive2://localhost:10000> show tblproperties plain_text;
OK
+-------------------------+-------------+
| prpt_name | prpt_value |
+-------------------------+-------------+
| EXTERNAL | TRUE |
| bucketing_version | 2 |
| numFiles | 1 |
| skip.header.line.count | 1 |
| totalSize | 24579945 |
| transient_lastDdlTime | 1594221042 |
+-------------------------+-------------+
TABLE SIZE IS same as CSV size 24579945 byte
Avro File Format
0: jdbc:hive2://localhost:10000>CREATE TABLE test_avro
(
id integer,
name STRING,
age integer
)
STORED AS avro;
Insert data into test_avro from plain_text table
INSERT INTO TABLE test_avro SELECT * FROM plain_text
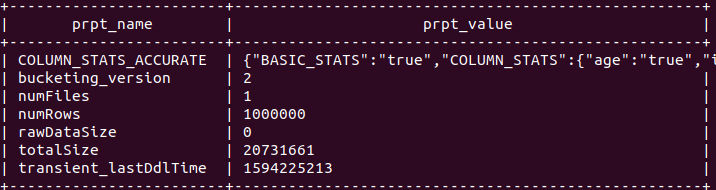
Check size of table
0: jdbc:hive2://localhost:10000> show tblproperties test_avro;
+————————+—————————————————-+
| prpt_name | prpt_value |
+————————+—————————————————-+
| COLUMN_STATS_ACCURATE | {“BASIC_STATS”:”true”,”COLUMN_STATS”:{“age”:”true”,”id”:”true”,”name”:”true”}} |
| bucketing_version | 2 |
| numFiles | 1 |
| numRows | 1000000 |
| rawDataSize | 0 |
| totalSize | 20731661 |
| transient_lastDdlTime | 1594225213 |
+————————+—————————————————-+
size is decreased to 20731661 bytes
Parquet File Format
Same as Avro we will create Parquet and ORC table and insert data from plain_text table
0: jdbc:hive2://localhost:10000>CREATE TABLE test_parquet
(
id integer,
name STRING,
age integer
)
STORED AS PARQUET;
0: jdbc:hive2://localhost:10000>INSERT INTO TABLE test_parquet SELECT * FROM plain_text ;
0: jdbc:hive2://localhost:10000> show tblproperties test_parquet;
ORC FILE FORMAT (HIGH Compression,FAST READ)
jdbc:hive2://localhost:10000>CREATE TABLE test_orc
(
id integer,
name STRING,
age integer
)
STORED AS ORC;
jdbc:hive2://localhost:10000>INSERT INTO TABLE test_orc SELECT * FROM plain_text ;
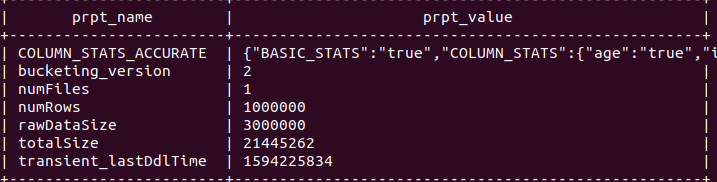
Check Size of table
0: jdbc:hive2://localhost:10000> show tblproperties test_orc;
+------------------------+----------------------------------------------------+
| prpt_name | prpt_value |
+------------------------+----------------------------------------------------+
| COLUMN_STATS_ACCURATE | {"BASIC_STATS":"true","COLUMN_STATS":{"age":"true","id":"true","name":"true"}} |
| bucketing_version | 2 |
| numFiles | 1 |
| numRows | 1000000 |
| rawDataSize | 104000000 |
| totalSize | 6149821 |
| transient_lastDdlTime | 1594225900 |
+------------------------+----------------------------------------------------+
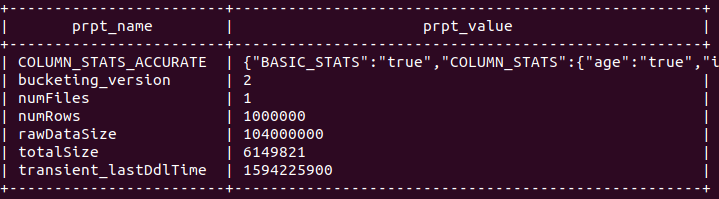
size is decreased to 6149821 ie 6.1 MB